NVMe: What
Reference:
What is NVMe
NVMe is a protocol between Host and SSD, which is attached to the upper layer of the protocol stack.

Any command made by NVMe is done by PCIe. Although NVMe's commands may be done by other interface protocols, NVMe's cooperation with PCIe is undoubtedly the strongest.
NVMe is born for SSD. Before the emergence of NVMe, the vast majority of SSD is taking the AHCI and SATA protocol, which is actually for the traditional HDD service. Compared with the HDD, SSD has a lower delay and higher performance, AHCI has been unable to keep pace with the development of SSD performance, thus has become a bottleneck restricting SSD performance. SSD needs PCIe and NVMe to take the place of SATA and ACHI, respectively.
NVMe has developed commands for communication between Host and SSD, and how commands are executed. NVMe has two commands, one called Admin Command, used to manage and control the SSD by Host; the other is the I / O Command, for the transmission of data between Host and SSD.
How does NVMe work
NVMe has three main components: Submission Queue (SQ), Completion Queue (CQ) and Doorbell Register (DB). SQ and CQ are located in the Host's memory, DB is located inside the SSD controller.

SQ is located in the Host memory, when Host intends to send a command, Host first prepares tne command in SQ, and then notifies SSD to take; CQ is also located in the Host memory, when a command is completed, whether successful or failure, SSD will always write command completion status into CQ. When Host sends a command, it does not send commands directly to the SSD, but puts the command in its own memory, and then tells the SSD by writing the DB register on the SSD side.

NVMe processing commands require 8 steps:
- Host writes the command into SQ;
- Host writes DB to notify SSD;
- SSD receives the notice, and fetches the command from the SQ;
- SSD processes instructions;
- When the instruction execution is completed, SSD writes the result into CQ;
- SSD sends a message to inform Host of the instruction completion;
- Host receives the message, processes CQ, and check the status of instruction;
- When Host processed the instruction results in CQ, Host replies SSD through DB: instruction execution results have been processed.
Look into NVMe Components
The relationship between SQ and CQ, can be a one-to-one relationship, or can be a many-to-one relationship, however, in any case they are paired.

There are two kinds of SQ and CQ, one is Admin, the other is I/O, the former stores Admin command for the Host management control over SSD, the later stores I/O command for data transfer between Host and SSD. There is only 1 pair of Admin SQ/CQ, but there are up to 65535 (64K - 1) I/O SQ/CQ. Each core in Host can have one or more SQ, but only one CQ.
The number of SQs used in the actual system, depends on the system configuration and performance requirements, the number of I/O SQs can be flexibly set. As the queue, each SQ and CQ have a certain depth: for Admin SQ/CQ, the depth can be 2-4096 (4K); for I/O SQ/CQ, the depth can be 2-65536 (64K). The queue depth can also be configured. SQ stores the command entry, whether Admin or I/O command, each command entry size is 64 bytes; CQ stores the state of the command completion entry, each entry size is 16 words Section.
DB, is used to record the Head and Tail of a SQ or CQ. Each SQ or CQ has two corresponding DBs: Head DB and Tail DB. DB is the register on the SSD side, which records the position of the head and tail of SQ and CQ.

Here is a queue of production/consumption models. The producer writes to the queue of Tail, and the consumer takes the head out of the queue. For a SQ, its producer is Host, because it writes the command to SQ's Tail position, the consumer is the SSD because it fetches the instruction execution from SQ's head; for a CQ, on the contrary, the producer is the SSD, because it writes the state of the command completion to CQ's Tail position, the consumer is Host, it reads the state of the command completion from CQ's header.
And here is a vivid example of NVMe command processing.
At first, SQ1 and CQ1 are empty, Head = Tail = 0.

Host writes 3 commands into SQ1, SQ1 Tail becomes 3. At the same time Host updates the SQ1 Tail DB register in the SSD Controller side to the value of 3, which tells SSD Controller that there is a new command that you need to take.

SSD Controller receives the notice, and then fetches the 3 commands to handle. At the same time, SSD Controller updates the local SQ1 header DB register to the value of 3.

SSD performs 2 commands, and writes 2 command completion information to CQ1, and updates the corresponding Tail DB register of CQ1 with a value of 2. Then SSD sends a message to the Host: there is a command completed, please pay attention to view.

Host receives notification from SSD, fetches the 2 command completion information from the CQ1. After that, Host writes the CQ1 Head DB register with the value of 2.

CQ Entry Field Explanation
There is a problem that is unfair to Host, i.e., Host can only write DB (limited to write to SQ Tail DB and CQ Head DB), cannot read DB.
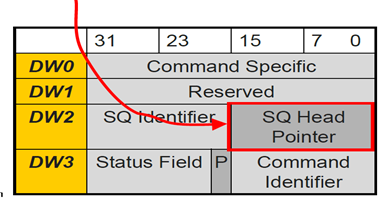
When SSD writes the command completion information into CQ, SSD also writes the SQ Head DB information. In this way, Host can have all information on SQ Head and Tail.
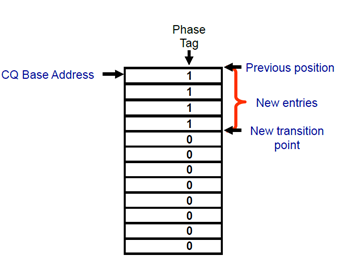
How about CQ? Host knows Head, do not know Tail. SSD informs Host by writing the "P" field in the CQ entry. Specifically, the "P" bit in each entry in CQ is initialized to 0, and when the SSD writes a command completion entry to CQ, "P" is written as 1. Remember that, CQ is in the Host memory, Host can check all the contents of CQ, of course, including "P". Host remembers the last Tail, and then checks "P" down one by one, finally Host can get a new Tail.
[Question] When is the "P" bit reset ?
Logic Block Address in NVMe
If Host wants to write user data to the SSD, it needs to tell the SSD what data to write, how much data is written, and where the data source is in memory. The information is contained in the Write command sent by the host to the SSD. Each user data corresponds to a thing called LBA (Logical Block Address), Write command tells SSD what data is written by specifying the LBA. For NVMe/PCIe, the SSD receives the Write command, reads the data from memory data location via PCIe, then writes the data to the flash memory, and obtains the mapping between the LBA and the flash location.
If Host wants to read the user data on the SSD, it also needs to tell the SSD what data, how much data is needed, and where the data needs to be placed in the Host memory. The information is included in the Read command sent by the Host to the SSD. Based on the LBA, SSD finds the mapping table, finds the corresponding flash physical location, and then read the flash to get the data. After the data is read from the flash memory, the SSD writes the data to the Host-specified memory via PCIe for NVMe/PCIe. This completes the Host's access to the SSD.
Host has two ways to tell SSD which memory location for the user data, one is PRP (Physical Region Page), the other is SGL (Scatter/Gather List).
PRP
NVMe divides Host's memory into lots of pages, the page size can be 4KB, 8KB, 16KB ... 128MB.

PRP Entry is essentially a 64-bit memory physical address, but the physical address is divided into two parts: page start address and page offset. The last two bits are 0, indicating that the physical address represented by PRP can only be accessed in four bytes (4B align). The page offset can be either 0 or a nonzero value.

PRP Entry describes the starting address of a continuous physical memory. If you need to describe a number of discrete physical memory? It needs a few PRP Entries. Linking a number of PRP Entry generates the PRP List.

As you can see, each PRP Entry offset in the PRP List must be 0, and each PRP Entry in the PRP List describes a physical page. The same physical page is not allowed, otherwise the SSD writes data to the same physical page several times, causing the data to be written first to be overwritten.
Each NVMe command has two fields: PRP1 and PRP2, Host leverages these two fields tell SSD the memory location of data or the address of data to be written.

PRP1 and PRP2 may point to the location of the data, or it may point to the PRP List. Similar to the concept of the pointer in the C language, PRP1 and PRP2 may be a pointer, a pointer to the pointer, even a pointer to the pointer pointer. According to different orders, SSD can always peel the layer of packaging, and find the real physical address of the data in memory.

PRP1 points to a PRP List, and the PRP List is located in the 50 offset in the 200th page. SSD determines that PRP1 is a pointer to the PRP List and fetches the PRP List in the Host memory (Page 200, Offset 50). After obtaining the PRP List, the real physical address of the data is obtained, and the SSD then reads or writes data to these physical addresses.
For the Admin command, it only uses the PRP to tell the SSD memory physical address; for I/O commands, in addition to using PRP, Host can also use SGL to tell SSD the physical address of data in memory to read or write.

Host will tell SSD what way to use in the command. Specifically, if the command DW0 [15:14] is 0, that is PRP way, otherwise it is SGL way.
SGL is a data structure, used to describe a data space, the space can be the data source space, or it can be the data target space. SGL (Scatter Gather List) is a List, constructed by one or more SGL Segment, and each SGL Segment is constructed by one or more SGL Descriptor. SGL Descriptor is the most basic unit of SGL, it describes a continuous physical memory space: the starting address + space size.
Each SGL Descriptor size is 16 bytes. A memory space, can be used to store user data, or can also be used to store SGL Segment. According to the different uses of this space, SGL Descriptor can be divided into several types.

There are four SGL Descriptor. One is the Data Block, indicating that this space is user data space; One is the Segment descriptor. SGL is a list of SGL Segments, since it is a linked list, a Segment needs to have a pointer to the next Segment. This pointer is the SGL Segment descriptor, which describes the space in which the next segment is located. In particular, the last second segment in the list, we call its SGL Segment descriptor the SGL Last Segment descriptor. It is essentially SGL Segment descriptor. The usage of SGL Last Segment descriptor may let the SSD know that the list is coming head, followd by only one Segement, when SSD is analyzing the SGL and encountering the SGL Last Segment descriptor. SGL Bit Bucket is only useful for the Host read, telling SSD that the data you write to this memory is discarded. Well, since Host does need the data, SSD will not pass it.

Here is a real example. In this example, assuming that Host needs to read 13KB of data in the SSD, which really requires only 11KB of data. The 11KB data needs to be placed in three different sizes of memory: 3KB, 4KB and 4KB.

Whether it is PRP or SGL, the essence is to describe a piece of memory in the data space, this data space may be physically continuous, or discontinuous. Host sets PRP or SGL in the command, to tell the SSD data source (write) or target (read) in the memory location.
The difference between SGL and PRP is: For a piece of data space, for PRP, it can only be mapped to a physical page, and for SGL, it can be mapped to any size of continuous physical space.

Look into NVMe and PCIe
The most direct contact between PCIe and NVMe is the transport layer. At the NVMe layer, we can see the 64-byte command, the 16-byte command status, and the command-related data. At the PCIe transport layer, what we can see is TLP (Transaction Layer Packet). In the NVMe command processing, PCIe transport layer uses Memory read/write TLP to serve NVMe in most cases.
Here is a trace at the NVMe and PCIe transport layer, check whether you can understand it with NVMe command processing prcedure.

Data Security in NVMe
In addition to the logical block data itself, NVMe also allows each logical block to have an assistant called Meta Data to ensure security.
There are two kinds of existence for metadata, one is as data expansion of logical block, and stored together with logic block data. Another way is to put the logical block data together, and the metadata is placed elsewhere.


The structure of metadata and the block with metadata is shown in the following figures, respectively.


The "Guard" is a 16-bit CRC (Cyclic Redundancy Check), which is calculated from the logical block data; "Application Tag" and "Reference Tag" contain information such as the logical address (LBA) of the data block. CRC check can detect whether the data is wrong, the latter can ensure that the data does not appear "Zhang Guan Li Dai" (mismatch) problem, such as LBA X uses LBA Y data, which situation is often caused by SSD firmware Bug. Anyway, NVMe can help you find this problem.
NVMe Namespace
An NVMe SSD consists mainly of SSD Controller, Flash space, and PCIe interface. If the flash space is divided into a number of independent logical space, each space logical block address (LBA) range is 0 to N-1 (N is the logical space size), then each logical space divided in this way is called NS. For SATA SSD, a flash memory space corresponds to only one logical space, and for NVMe SSD, a flash memory space can corrspond to multiple logical spaces.
Each NS has a name and ID, and ID is unique, the system distinguishs between different NS through the NS ID. As shown in the following example, the entire flash memory space is divided into two NS, NS A and NS B, respectively, the corresponding NS ID is 1 and 2, respectively. If NS A size is M (in logical block size), NS B size is N, their logical address space is 0 to M-1 and 0 to N-1, respectively. When Host read and write SSD, the NSID is needed to specified in the command to indicate which logic block in NS to read or write.

An NVMe command takes up a total of 64 bytes, where the 4th to 7th Byte specifies the NS to be accessed.

For each NS, there is a 4KB size data structure to describe it. The data structure describes the size of the NS, how much the entire space has been written, the size of each LBA, and the end-to-end data protection settings, whether the NS belongs to a Controller or several controllers can be shared, and so on.

NS is created and managed by the Host. Each created NS, from the point of view of Host OS, is a separate disk, user can do partition and other operations in each NS.

In the above example, the entire flash memory space is divided into two NS, NS A and NS B, the OS sees two completely separate disks.
In fact, NS is more applied to the enterprise level, create different characteristics of the NS according to the different needs of customers, that is, create a number of different features of the disk (NS) in a SSD for different customers. Moreover, another important usage occasion of NS is: SR-IOV.

As shown in the figure above, the SSD acts as an Endpoint for PCIe, implements a physical function (PF), and has four virtual functions (VF) associated with the PF. Each VF has its own exclusive NS, and the public NS (NS E). This feature allows virtual functions to share physical devices and perform I/O without CPU and hypervisor software overhead.
In addition to a number of NS, an NVMe subsystem can also have a number of SSD Controller. Moreover, it can have several PCIe interfaces as well.


[Question] Since there is SR-IOV support for NVMe (NS), is there any need to implement MPT for NVMe in Qemu?
A: For this question, I think there are 2 main reasons. (1) SR-IOV support for NVMe (NS) is not mature currently. (2) SR-IOV suffers from hardware complexity and circuit resource limitation, which impacts its scalability.